
猪脚说第四期


容易忽视的 bug
新的开始
1 |
|
以上代码想要实现这样的功能:每当输入一个单词时,在现有单词表wordlist里查找其是否已存在。若查找成功,则输出YES,否则输出No。
细心的同学很快能发现问题:这段代码只是让flag初始值为 0,只要有一次查找成功之后,flag的值会一直 1,不会改变。因此在此之后,无论输入什么样的单词,都会输出YES!
一种正确改法是,让flag获得“新的开始”。即每次进入while循环后,进入for循环之前,都执行一步flag = 0;,让其在每一次查找的初值都为 0,便成功 de 出了 bug。
scanf函数返回值
在与同学们的交流中,我们发现同学们对于scanf函数的返回值不太清楚,下面举一个例子
1 |
|
我们直接给出程序的输入和输出结果:
1 | <input> |
我们再多给出一些输入输出样例:
1 | <input> |
通过上述例子我们发现:
scanf函数的返回值并不是输入的数据,而是其具体输入的有效数据的个数(这个太容易忽略了!);若
scanf函数中输入了非法的值(如第二个样例),则不会改变那一个数据的原始值,且返回值(输入的有效数据个数)不会算上此次非法输入。
因此,当遇到第二次作业第五道编程题(小型图书管理系统)时,不能采取如下做法:
1 | while ((scanf("%d", &op)) != 0) { |
因为,无论你输入的是操作 1、2、3还是0,scanf函数的返回值都为 1。所以我们推荐如下写法:
1 | while (scanf("%d", &op) != EOF) { |
一些字符判断函数的返回值
很多同学喜欢使用声明(啥是声明啥是定义?还记得吗?)在<ctype.h>中的库函数,例如:
1 | int isupper(char c); // 判断一个字符c是否为大写字母 |
需要注意的是,在大多数编译环境中,这些函数的返回值类似于strcmp函数,只有零和非零值(不确定)两种情况,所以形如
1 | if (isdigit(c) == 1) { |
这样的写法是有巨大隐患的。
事实上,**if语句条件不成立当且仅当括号中的表达式值为0或'\0'或NULL,所以,任何其他非零值都会进入if分支。以<ctype.h>库函数为代表的 C 库调用,标准写法**是
1 | if (isdigit(c)) { |
上述代码会在我们脑海中直观地翻译为“如果是数字,怎么怎么样;否则怎么怎么样”,这种写法不是更贴近自然语言的语义吗?这一个小小的细节,足以充分体现【函数命名规范】和【代码书写规范】的重要性。
数据结构引入
过去几周我们复习了诸多知识点,也学习了若干新内容,这是为后续课程做铺垫。再次简要列举必会知识点,请自行查缺补漏,后续如果出现下列基本知识的迷惑,我们的回复将包括但不限于「自己百度一下」「自己 csdn一下」「看猪脚说」「看程设课件」等。
- 基本的递归函数的使用
- 全排列等题目确实较难,但求解斐波那契数列你得会
- 一维数组
- 初始化
- 数组名的含义
- 数组作为函数参数
- 字符串
- 字符数组和字符串常量的区别
- 字符串读取,
scanf和gets和fgets等的区别(以后再出现逐个字符构造字符串忘加'\0'的问题统一回复自己 de) - 字符数组初始化
- 字符串处理函数
strstrstrcmpstrcpystrncpystrcatstrncatstrlenstrchr等的功能、参数类型与顺序、返回值类型与含义 char与int的联系和区别
- 文件操作
- 打开文件
- 关闭文件
- 读文件:单个字符 / 一行 / 按指定数据类型
- 写文件:单个字符 / 一行 / 按指定数据类型
<ctype.h>- 判断是否为字母
- 判断是否为大写
- 判断是否为小写
- 判断是否为数字
- 判断是否为数字或字母(
isalnum) - 判断是否为空白字符(
iswhite) - 判断是否为标点符号(
ispunct) - 转成大写
- 转成小写
- 二维数组
- 定义与初始化
- 作为函数参数
- 遍历方式
- 指向行的指针(数组指针)
- 指向列的指针(基本类型指针)
- 指针
- 指针的定义与初始化,什么是
NULL - 不同类型的指针的区别和联系
- 取地址(什么是地址),解引用
- 字符指针和字符数组的区别和联系
- 什么是
void* - 指针的
++--和加减运算 - 给指针赋值的含义
- 数组名和指针的区别与联系
- 函数参数的值传递
- 指针数组,管理字符串常量的指针数组
- 数组指针和函数指针(不要求熟练掌握)
main函数的命令行参数
- 指针的定义与初始化,什么是
- 结构体
- 结构体的声明
- 结构体变量或数组的定义与初始化
- 结构体成员的访问
- 结构体的赋值
- 指向结构体的指针及通过指针访问成员
- 类型别名的声明及其与
#define的区别和优劣 - 自引用结构的概念(后续继续深入学习)
qsort函数(以后不要用冒泡了!)- 包含在哪个头文件?
- 有几个参数?顺序?含义?
cmp函数怎么编写?- 基本类型数组的升序 / 降序(
double类型的比较要注意什么?) - 二维字符数组字典序
- 二维基本类型数组多关键字
- 结构体数组单关键字 / 多关键字
- 基本类型数组的升序 / 降序(
sizeof的使用,当参数为- 类型名的时候
- 变量名的时候
- 指针变量名的时候
- 数组名的时候
接下来我们将要学习的是数据结构正文部分,作为数据结构,理应与工具的使用(C 语言语法、IDE 的配置等)脱钩,而专注于理论知识和编程实现本身。所以希望同学们尽早排除干扰项,这样,课程本身的学习也会更加轻松。
什么是数据结构
我们不谈文邹邹的东西,虽然选择题可能会考。如果诸位手上有《离散数学(第三版)》,不妨翻到后面“图”和“树”的章节,看看书中是怎么定义的,虽然这些内容离散 1 不教。


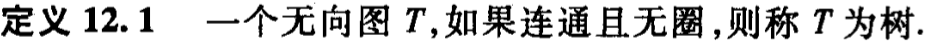

我们注意到,未来我们将学习的一系列数据结构,都是通过自然语言和数学符号定义的,这和 C 语言有什么关系呢?首先,想必大家已经大致了解了“链表长啥样”“树长啥样”“图长啥样”,在此基础上,我们可以说,各个类型的数据结构,只是一种逻辑上的定义,是人们在纸面上画出来的东西、是通过数学方式总结的东西。这里,我们用“东西”当作宾语,似乎显得有点抽象了。且听我们逐细言来。
硬件与物理
计算机不是魔法,是由硬件组成的,比如电线、二极管、塑料等。所以大家应该意识到,你的每一次操作(点击鼠标、摁下键盘、开启网页、执行int a = 0;),归根结底,是某些电流的流动、某些开关的开闭、高低电压的转换,甚至可以细化到电子在你看不到的地方跃迁……
不管怎么说,作为一个纯物理的系统,计算机需要极其复杂的设计。这种设计给我们两点启发:其一,有赖于高性能的硬件,计算机可以用于快速处理海量的数据,效率远高于人;其二,给定一台计算机,其体系结构已经定死,其能够支持的功能必然有限。事实上,这个问题的妙处就在于:我们手里只有有限的资源,但我们利用想象力,可以解决一切问题。
计算机为我们提供了内存、硬盘(磁盘)等物理设备存放数据。当程序中定义了一个接一个的变量,它们大概率会被放在一起;当程序中定义了一个数组,内存提供一片连续的空间存放;另外,我们有指针这种工具,可以间接地引用某一片内存空间。前两者对应连续存储方式,这不难理解;而后者为我们提供了一种新的思路
- 对于每一项数据,我们为其增加一个成员 —— 用于记录地址的成员 —— 将其打包成一个数据包。
- 每次新增了数据需要存放,我们在内存中申请一片空间用于存储。
- 新增的数据包的地址,会被先前已经存在的数据包中的那个记录地址的成员记录下来,以便通过已经存在的数据包,访问到新的数据包。
当然对应到 C 语言中,新增的那个成员就是指针,打包过程即声明struct,申请空间通过malloc,后续操作涉及指针的赋值等。于是,不同于连续存储,一种链式存储的方式诞生了。我们只需要记录下某一些节点的位置,通过其中的指针成员不断向后访问,即可以找遍所有节点。由于指针想指谁就可以指谁,因此这些节点之间的结构可能有以下几种
- 第一个节点指向第二个,第二个节点指向第三个,……。这种链式结构,即为链表。
- 从一个根出发,不断向后分叉。这种分叉结构,即为树。
- 乱指来指去。这种乱七八糟结构,即为图。
So What?
上一小节我们从物理硬件的支持和编程语言提供的手段,描述了一种新的存储方式。我们可以进行如下思考
- 比起刚才提及的链式存储,数组这种连续存储方式似乎更加浅显易懂;而链式存储似乎更加灵活,因为我们可以自由地排放数据的先后顺序(前提是指针不出错)。
- 某些情况下,这两种存储方式可以相互转换。例如,链表的一个接一个的存储方式,和数组也很像 —— 反之同理 —— 区别在于数组的每一个元素在内存中真的连续存放,而链表的元素离散地存放,我们只能通过指针一个接一个地访问。再比如,图的这种一个节点可以随意和其他节点连在一起的模式,似乎用数组也能做到 —— 给每个点编号,然后把相邻的节点的编号都存入一个数组里。
- 这些不同的结构,可以用于实际问题中的仿真。数组 / 链表的结构像是在排队,能不能用来模拟生活中进进出出的排队问题(如航班的离港序列、银行排队与服务)呢?图能够仿真生活中管道的铺设、道路的布局等,能不能用来求最短的路径、最少的工程用料?我们发现,不同的结构都具备了描述现实世界的强大潜能。
- 上述的各种结构与计算机的运行原理密不可分。试想,同为线性结构的数组和链表,想在中间插入一个新数据,前者需要把该位置之后的所有元素,都往后挪一个位置,然后把新元素插进去;而对于后者,需要为新数据申请一片空间,然后修改一些指针的值,使得一些指向关系发生变化,从而在逻辑意义上实现了“插入”。
- 数组插入写起来比较容易,但是需要计算机搬运很多个元素,看起来有点浪费时间。
- 链表插入有点抽象,但是实际上只需要修个几个指针的值,快速便捷;但是如果要查找一个数据,我们必须从链表的头开始,一个接一个地往后通过指针访问每个节点,这种操作好像也很麻烦。另外,对于链表,我们也就不能用
qsort等进行排序了。
总结
前两节我们说了两件事:其一,计算机作为工具,为我们提供了存放数据的不同方式、不同结构、不同逻辑;其二,这些不同的方式似乎各有特点,各有优劣。以上所讨论的,都是数据结构相关的内容,所以我们在最早的时候,将数据结构描述为一样“东西”,确有其道理。所以,数据结构可以理解成以下几部分内容
- 海量的、相互之间有关联的数据,在计算机中应如何组织(线性的排排队还是分叉结构还是其他)
- 确立了组织方式,基本的数据操作(插入、删除、查找、排序)应该如何编程,有无更加高效的写法
- 作为描述现实世界的工具,能否利用数据结构模拟实际问题(管道铺设、最短路径)
- 数据结构本身也是数学研究的对象,能否基于数学原理、利用编程工具,解决一些数学问题(利用树实现表达式的计算?有点玄乎。。。)
由于本周没有太多新知识,因此写了这样一篇文字作为接下来学习的 introduction。如果你能看到这里,那么也祝愿你在数据结构的学习中取得收获与进步~
第三次作业补充练习
1、干员整理 ,这是适合现阶段练习结构体用法的一道非常综合的题目,由北航 AK 宝典制作小组提供,初次登录网站需要注册,建议账号为自己的学号。
2、字符串之海 ,这道题可以作为第三次作业第五题(词频统计)的补充练习,很适合大家熟悉链表的使用。
Author: diandian, Riccardo
- Title: 猪脚说第四期
- Author: Diandian
- Created at : 2023-07-14 17:54:41
- Updated at : 2023-07-14 18:00:27
- Link: https://cutedian.github.io/2023/07/14/猪脚说第四期/
- License: This work is licensed under CC BY-NC-SA 4.0.