
猪脚说第二期


写在前面 —— 关于理论与实验
我们可以很负责地告诉大家,几乎所有的计算机软件核心专业课(如计算机组成原理、操作系统、编译原理、计算机网络等),都由理论和实验两部分构成。前者,基本建立在抽象的层面上,一般以文字表述和数学公式给出;后者,基本需要个人在实践中完成。实验的内容一般由指导书、手册等给出,需要自行阅读了解;而其中涉及的工具和方法,如虚拟机、编程工具、编程语言等,完全通过自学解决。
幸运的是,作为一门承上启下的课程,数据结构课的重点知识并非仅纯数学符号。由于我们的学习进度尚有限,这门课在日常教学中也融入了大量 C 语言代码,并且几乎可以当作“板子”。所谓板子,就是可以直接拷贝黏贴的东西,
每到考试,也会出现打板子、拼接板子等现象。这给我们两点启发。其一,很多知识在课件里就能找到,当同学们遇到困难时(如文件操作、结构体),不必等老师讲授,自行看课件、搬运代码,很多问题就能迎刃而解。其二,我们必须强调自学的重要性,善于通过各类渠道解决问题。举个例子,仅通过搜索引擎,就可以查询到近来上机出现的诸多问题。
此外,由于实验的基本形式是选填和编程题,而非从零开始迭代着制造一个东西,所以就没有指导书的必要。我们的“猪脚说”则作为上机实验的补充指导,解答共性问题、提供知识总结,希望对大家有所帮助。
常见问题汇总
为什么我本地测试正确,提交运行却出现了多余字符?
数组是一片连续的内存空间,数组之外的内容是不可控的。当我们越界访问时,有可能成功,有可能报错,有可能读取到随机内容。因此,这类问题的主要原因是数组开得不够大和未初始化。
(1) 数组大小。题目不一定给出明确的数据范围,如果有数据范围,比如 80,则开到100 比较合适,甚至 200、500 等都不过分。如果没有数据范围,则根据经验考虑,如字符数组开 512 或 1024 大小,整型数组开 200、1000 等。一般不会在数据范围的问题上为难大家,但如果开得和题目说的一样大,确实更容易出错(如忘了字符串末尾的'\0',下标从 1 开始等)。
(2) 初始化。很多时候都需要把一个数组或变量初始化成 0。考虑这样一种情况,我们逐个字符地构造一个字符串,结果最后忘了添加'\0',如果这个字符数组先前被初始化成全 0,则字符串的后面还是有'\0'的;如果未初始化,字符串后面的内容则是未知的,极有可能出错。下面给出一些常见的初始化方式。
1 | // 以下代码都处在 main 函数中 |
(3) 全局变量。全局变量会执行默认初始化,一般自动初始化成 0;且在各个函数中都能直接访问,简化了参数列表。但正如同先前谈到的代码风格问题,频繁使用全局变量并不是一个好习惯。一般地,只有需要很大的数组,如int [1000000],或常量,如const int MAX_LENGTH = 1024;的时候,才会使用全局变量。
为什么错误输出和期望输出一模一样还会 WA?
这种问题多数是由于通过printf("%c", c);的方式输出导致的。在打印过程中,可能不慎打印了空白字符。空白字符在网页上显示不出来,但在评测机进行比对的时候,就会认为错误。解决的方法是,在本地把代码改成printf("%c0", c);(我们假设正确的输出中不含 0,如果有冲突就换一个字符),这样如果输出了诸如a0b0c00的内容,就说明在最后一个 0 的前面还输出了不可见字符。打印了空白字符很可能是为字符变量赋值或初始化的逻辑有漏洞引起的,需要结合代码具体分析。
为什么这种不合法的情况也还是会输出啊?
没有按照题目要求输出内容,多数是代码逻辑的问题引起的。我们仅以第一次作业的“拓展字符”为例,看一种典型的错误。伪代码如下
1 | 遍历字符串: |
对于合法的可拓展字符,这段代码可以成功拓展。考虑 “g - a” 这类情况,程序会先连续进入两个if,但是d算出来为负数,所以for循环不执行,好像也符合要求。但是,一旦进了第一个if,则else分支原样输出将不被执行。这就是典型的逻辑漏洞。
另外,多数情况下的“运行超时”都是死循环导致的,这与代码逻辑也密不可分。
解决逻辑问题的常见手段是调试。如果你尚未掌握自己所用 IDE 的调试方法,不妨在程序的多个地方打印变量的值,观察程序的运行过程;如果需要判断是否进入某个分支、循环多少次等,也可以采用打印的方法。通过有效的工具手段和纸面演算解决程序逻辑问题,是每个人必备的基本功。当然,将代码提取成函数,也有助于缩小错误的范围。
qsort函数详解
1 |
|
该函数可实现的功能是:按照某种自定义的规则( cmp函数),对数组base的 num个元素进行排序。
想要理解qsort函数的具体实现方式,我们首先引入回调函数的概念:
回调函数就是一个通过函数指针调用的函数。如果把函数的指针作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,就说这是回调函数。
显然qsort函数的四个参数中,**cmp参数就是回调函数,我们需要使用它来指导qsort函数的进行**。当qsort函数想要确定某两个元素的排列顺序时,会将这两个元素的指针 p1 和 p2 传入cmp函数进行元素值的比较:
如果
cmp函数返回值小于 0,则 p1 所指向元素会被排在 p2 所指向元素的前面;如果
cmp函数返回值等于 0,则 p1 所指向元素与 p2 所指向元素的顺序不确定(因为在某种意义上两个相同的元素谁在前谁在后都无伤大雅);如果
cmp函数返回值大于 0,则 p1 所指向元素会被排在 p2 所指向元素的后面。
可是,设计者在设计qsort函数时,不知道使用者会排序什么类型的元素,qsort函数自身也不清楚数组元素的类型是什么,但是它又必须实现元素两两之间的比较与交换。怎么办呢?最高效的方式就是从数据的存储入手,我们只需要将两个数据所占有的内存的内容交换【可以表述成:将属于 p1 的若干个抽屉的内容全部取出,将属于 p2 的若干个抽屉的内容全部取出,两者交换(详见猪脚说第一期😋)】便可实现任意类型元素的排序了。
需要交换的字节大小视具体情况而定,这时候参数width与cmp函数里的void *的作用就体现出来了。
void *称为通用指针,它就像一个垃圾桶,什么地址都可以往里扔,我们需要做的只是在自己写的cmp函数里对扔进来的地址做强制类型转换,再通过width参数规定所交换字节内容的大小,如sizeof(int)、sizeof(char)、 sizeof(struct Node)等,就可以使qsort函数按你所需地对目标数组元素进行排序。
现在我们以一段实操代码为例,感受qsort函数的使用方式:
1 |
|
通过我们自己写的cmp函数得知,当返回值小于 0(即 e1 所指向元素小于 e2 所指向元素时),e1 所指向元素会被排列在 e2 所指向元素的前面,且每次严格按照int类型所占有的字节宽度为限度进行交换,由此可实现数组 a 中所有元素由小到大排序。
当然,若想实现元素由大到小排序,只需将cmp中内容改写为return (*(int*)e1 > *(int*)e2) ? -1 : 1;
值得注意的是,若对于double类型数组进行由小到大的排序,我们需将cmp函数写为:
1 |
|
学习结构体的意义在哪儿
结构体的声明、定义和使用都相对简单,结合课件即可掌握。较新的内容是指向结构体的指针,建议忽略本质、注重语法和使用,随着一两周后链表的学习,很快即可上手。
先来考虑这样一种需要处理的情形:一个班级里有若干学生,每个学生的学号、姓名、成绩三个信息需要被记录,现在我们需要对其中的某些学生的信息进行数据处理,声明结构体如下:
1 | struct student{ |
显然,如果我们只需要记录一位学生,大可不必使用struct student kid;的定义形式,也不需要在后续访问变量时使用kid.number、kid.name、kid.grade如此繁杂的方式。我们只需要分别定义两个字符串数组、一个int类型变量即可,此时为了某种程度上的整洁而声明结构体类型、定义结构体变量反而显得多此一举。
可是,一个班级的整体数据肯定不能只由一位同学代表,往往我们需要处理多达上百个同学的数据,这时结构体的优势就开始显现。如果我们借助结构体变量的数组存储,那么只需要定义struct student info[200];后续每个学生的学号、姓名、成绩均可以作为成员储存在一个结构体变量中。
虽然我们仍可分别定义以下三个数组储存学生信息,每个学生的信息一一对应地储存于各数组中:
1 | char stu_number[200][20]; |
显然,若我们需要了解第 i+1 个学生的信息(假设数组下标从 0 开始),我们可以直接在info[i]这一结构体变量中全部寻得,也可以通过依次访问stu_number[i]、stu_name[i]、stu_grade[i]寻得。但前者不是更简洁方便、显得整体化吗?
因此,我们可以这样说:结构体存在的意义在有数组时才能体现。
但是,如果只需完成类似于统计班级里有多少同学姓“王”、有多少同学成绩在 90 分以上这样的任务,大可以使用上述三个数组,用遍历的方法求得满足条件学生的总数,似乎数组完全可以代替结构体变量,并且不会导致任何工作量的增加。这是因为这样的任务并没有把学生的三个信息建立起联系,对某一个信息进行统计的时候可以完全不用顾虑其他信息与之对应。
那么问题来了:当需要将学生的成绩按照由大到小的顺序输出,并同时输出每个同学对应的姓名与学号,使用哪种方式更好呢?
对于这个问题,刚刚学习了qsort函数的你想要进行实践。若你使用常规的数组存储,很快便遇到了困难。你并不知道qsort函数每次是对哪两个具体元素进行了比较,因此你单纯地将stu_grade数组排好了序,但其余两个数组与stu_grade数组的对应关系已经完全丧失,再无可能正确地输出每一个成绩所对应的姓名与学号。
但如果用qsort函数对结构体进行排序呢?
通过前文的讲解我们知道,我们的**cmp函数规则应该是对于每个结构体中的grade变量进行比较,但比较后的结果,是交换这个结构体变量所拥有的全部字节内容,而这个内容中既包含了grade、也包含了number[]和name[],因此我们便做到了在保留原有成员变量一一对应关系的基础之上,对学生成绩进行了排序**。
综上所述,在排序这样一个实际例子中,结构体变量存在着至关重要的意义与价值。
当然,结构体还有许多的应用场景,比如大家后续所要学习的链表……这里我们就不再详述。
另值一提的是,请同学们看看如下代码是否正确:
1 | int cmp(const void *e1, const void *e2) |
如果cmp函数内容如上所示,则使用qsort函数排序会出现奇怪的错误。原因是因为**类型转换符(type *)的运算优先级低于箭头运算符->**。所以会先计算e2->grade,再去做类型转换。因此正确写法为:
1 | int cmp(const void *e1, const void *e2) |
标准 C 库文件 I/O
文件 I/O,即文件的输入输出(Input / Output),几乎是每一个软件项目必备的模块。此外,我们称读取一个文件的内容为“读文件”,称编辑一个文件的内容为“写文件”。
以 macOS、Linux、Windows 为代表的多数操作系统,都引入了文件的概念。资源即文件。文件不仅包括屏幕上显示的一个个“文件”,还包括各类设备,如鼠标、键盘、打印机、屏幕(标准输出)、音响、U 盘等。一般来说,我们接触到的文件有两类 —— 文本文件和二进制文件。前者,可以理解为字符构成的有序集合,如 filein.txt 文本文件、test.c 源代码文件;后者的典型代表是 a.exe 这类可执行文件。特别要注意,word 等工具编辑出的 .docx 文件属于二进制文件,是不能直接用我们接下来要讲到的文件操作函数处理的。
这门课程涉及的文件操作无非基本的读写,可以理解成程序中字符数组里的内容与文件间的交换。关于判断文件是否存在、文件的创建 / 删除 / 复制 / 移动 / 重命名等操作,感兴趣的同学可以自己了解。
文件与目录
操作系统中的文件构成一个树状结构。
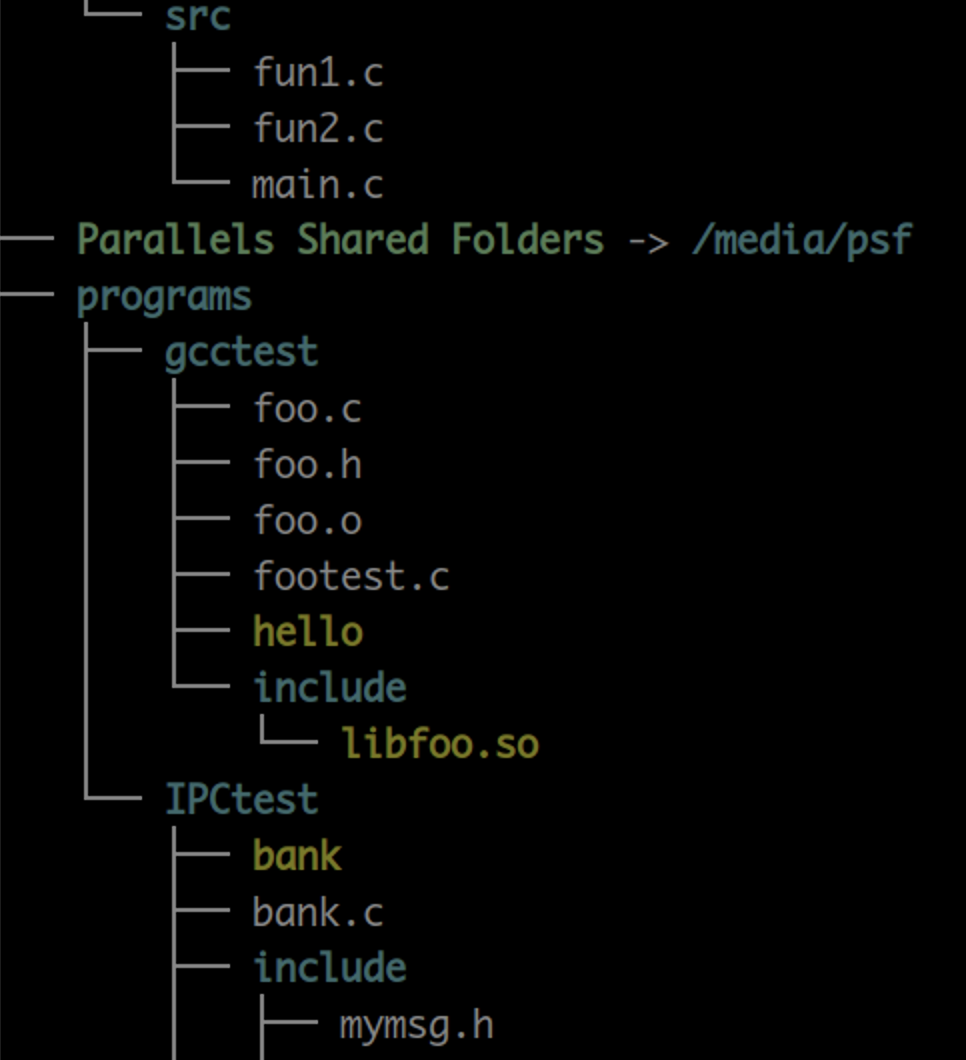
文件系统从一个根出发,每个文件夹就是树枝的分叉、每个文件就是树叶。这里的文件夹,就是目录。目录下可以包含若干文件,也可以为空。目录本身也是文件,是一种特殊的文件。目录中默认有两个隐藏的文件,文件名为.和..,分别表示自身和父目录。
定位一个文件,就需要给出文件的路径。一种方法是从根开始,一路写到当前文件,如D:\MyFiles\DSLearning\main.c,这就表示打开 D 盘,进入 Myfiles 文件夹,进入 DSLearning 文件夹,就可以找到 main.c 文件。这种方式称为绝对路径。另一种方法是,以当前所在的目录为基准点,描述目标的相对位置。以上图为例,假设我们处在 gcctest 目录下,则 foo.c 文件可以直接写foo.c或./foo.c(因为.表示当前目录),libfoo.so 文件可以写成 include/libfoo.so,bank.c 文件可以写成../IPCtest/bank.c(因为..表示父目录)。
上文中提到“当前所在目录”,可以简单理解为程序运行的目录,即 .exe 文件所在的目录。一般来说,把文件和 .exe 文件放在一起,在函数调用时直接指定文件名即可。
标准 C 库文件操作函数
在学习 C 语言的第一天,我们就知道要#include <stdio.h>,std 即 standard,io 即上文所述。我们调用的printf等,正是 C 库提供的 I/O 函数。调用以下函数,也应包含此头文件。
文件的打开和关闭
1 | FILE* fopen(const char *pathname, const char *mode); |
这里的“文件指针”
FILE*,是在<stdio.h>中定义的一个结构体指针,该结构体包含了一个文件的各类信息。1
2
3
4
5
6
7
8
9/* 此代码块内容仅供了解 */
typedef struct iobuf {
int cnt; // 剩余字节数
char *ptr; // 下一个字符的位置
char *base; // 缓冲区的位置
int flag; // 文件访问模式
int fd; // 文件描述符
// 还有很多
} FILE;获取了一个文件的文件指针,将其作为参数传递给其他函数,即可读写对应的文件。很多时候,文件打开会失败,则
fopen返回NULL。因此,建议同学们以以下方式打开一个文件。1
2
3
4
5
6// 示范代码,这部分代码位于 main 中
FILE *fp = fopen("filename", "r");
if (fp == NULL) {
perror("fopen error"); // 此函数在 <stdio.h> 中,能帮助输出错误信息
exit(1); // 此函数在 <stdlib.h> 中,能强制结束程序
}fopen函数的第一个参数为文件路径,前文已经说明。第二个参数指定打开方式,常见的是"r"和"w"。前者表示读,后者表示写。读文件,要求文件已经存在,否则会打开失败;写文件,默认不存在则创建,如果存在且已经有内容,则清空后从头开始写。程序运行时默认已经打开了三个文件 —— 标准输入
stdin、标准输出stdout、标准错误stderr,这是三个文件指针,分别对应键盘、屏幕、屏幕。
使用
fopen打开一个文件,则应当使用fclose关闭。当然做编程题的时候不写也没事。但是,这种规范操作仍应当强调,即便你可能并不会在意。当然,如果日后你因为忘记 close 或 free 而导致一个实际项目出现 bug,你一定会有所感悟的。
读文件
通过fopen获得文件指针后,可以调用相关 I/O 函数读写文件。
1 | char* fgets(char *str, int size, FILE *fp); |
1 | int fscanf(FILE *fp, const char *format, ...); |
1 | int fgetc(FILE *fp); |
写文件
这里仅提供函数原型,使用与非文件 I/O 版本无异,只是多传入一个文件指针而已。写文件时,应指定fopen打开模式为"w"。
1 | int fputs(const char *s, FILE *fp); |
文件偏移量
我们在读写文件时,很自然地会认为我们是不断向文件尾部读取或添加内容。假如读完一个文件,还想再读一遍,一种做法是先 close 再 open。那我们能不能像实际编辑文件那样在读完一部分内容后,跳到前面再读一遍,或者是在文件中间插入内容呢。正如同使用 word 时的那个不断闪烁的光标,当我们操作文件的时候,FILE 结构体也在维护一个文件偏移量,它指的是距离文件头的字符数(准确是是字节数),文件的读写,都是从当前偏移量开始往后进行的。
使用fopen打开文件时,文件偏移量为 0,即光标位于文件头。当我们不断读取内容,光标不断后移,则文件偏移量不断增大。当文件偏移量等于文件字节数(一般等于文件字符数 / 文件大小)的时候,就读到了文件末尾。
一个很显然的想法是,不同的文件读取方式,每次文件偏移量的增量也不同。例如,刚打开一个文件(假设其中的内容足够多),连续调用两次**fgetc,则每次偏移量加一;调用fgets,则偏移量从第一行的第三个字符跳到行尾;再次fgets,则偏移量跨过第二行跳到第二行行尾;进行fscanf,假设格式串为"(%d,%d)%c%lf",且第三行的数据类型符合要求,则文件偏移量跳过 1 个字节吞掉**(、跳过 4 个字节读取int、跳过 1 个字节吞掉,、跳过 4 个字节读取int、跳过 1 个字节吞掉)、跳过 1 个字节读取char、最后跳过 8 个字节读取double。
介绍文件偏移量有助于我们理解文件的写入和读取顺序,如果想要手动设置文件偏移量,实现更加复杂的文件操作,请自行学习fseek等函数。
第二次作业补充练习
Author: diandian, Riccardo
- Title: 猪脚说第二期
- Author: Diandian
- Created at : 2023-07-14 17:12:46
- Updated at : 2023-07-14 17:25:34
- Link: https://cutedian.github.io/2023/07/14/猪脚说第二期/
- License: This work is licensed under CC BY-NC-SA 4.0.