
猪脚说第三期


声明与定义
注意
在此课程中,使用结构体的时候请确保源代码文件是
.c后缀而非.cpp。C++ 中的结构体和 C 完全不同,或者说,C++ 里的struct不是结构体,而是类(class)。C++ 和 C 语法相近,但很多细节存在差异,甚至可能导致截然不同的编译错误和运行结果 —— 水很深,请谨慎!
声明(declaration)
当我们写下
1 | struct mystruct |
的时候,我们声明了一种自定义的结构体类型。其中,
struct是结构体关键字(key word),struct mystruct是类型(type)。struct不是任何类型,仅仅只是一个关键字;struct mystruct是类型,是和intdoublechar等并列的数据类型,并且是复合数据类型。
但是,上文的写法单纯是类型的声明—— 它指明了这一新类型应该长什么样 —— 含有一个int成员、一个double成员和一个char数组成员。于是我们有了一些新名词:成员变量(member variable)、字段(field)、域(field)、属性(attribute),从某种意义说上它们是等价的。
类型别名
上述声明的自定义复合数据类型为struct mystruct。这种类型写起来比较复杂,所以可以为之起一个别名
1 | typedef struct mystruct Type; |
此后,任何用到struct mystruct类型的地方,都可以用别名Type指代。此外,我们也可以另外为指向该结构体的指针类型起一个别名
1 | typedef struct mystruct * Type_ptr; |
当然,在声明结构体的同时就可以为新类型起别名
1 | typedef struct |
我们注意到,上述代码片段中struct关键字后并没有结构体原本的名字,这种无名的结构体,要么需要在声明的同时为之起别名,以便在后续程序中使用这一类型;要么必须在声明后立即定义相关变量(详见下文)。
补充
我们用到的很多头文件中都进行了大量别名的声明。
FILE类型其实是一个结构体,为了使之更加贴近英文语义,所以为之起了别名
2
3
4
int fd;
// much more...
} FILE;
size_t是用于描述字节数或“大小”“长度”的类型,如sizeof的返回值、数组大小等
部分字符串处理函数中,会使用
ssize_t类型表示字符串的长度
操作系统中,为进程编号(Process ID)类型起了别名
部分同学为了书写简便,为long long起了别名
定义(definition)
当我们写下int a = 10;的时候,定义了一个整型变量。我们有了自己的类型struct mytype,为之声明了别名Type,为其指针声明了别名Type_ptr,我们也可以定义此类型的变量和数组。
1 | struct mytype t1, t2; // 两个结构体变量 |
当然我们可以在声明结构体的同时定义变量和数组
1 | struct test |
如果声明的同时用typedef起了别名,则不能在其后直接定义变量。
前面提到的无名结构体,如果没有在声明的同时为之起别名,则只能在声明的同时定义变量和数组
1 | struct { |
很显然,我们在后续的程序中只能访问v1 v2 v3,而不能再定义此类型的变量或数组了 —— 因为这个类型没有名字。
注意:请严格区分声明与定义!
前向声明
我们知道声明结构体的时候不能嵌套,如struct A { struct A a; };,因为这会造成无穷的嵌套,导致报错。那么假设两个结构体相互引用对方,并且均采用了类型别名的形式,会不会出现问题呢?
1 | typedef struct A { |
当编译器读到结构体 A 的声明时,它发现需要有一个类型type_B的指针变量,然而type_B声明在后方,编译器暂时不知道其存在。假如把 A 和 B 的声明顺序对调,同样存在这一问题。
解决方法是使用前向声明(forward declaration)。
1 | typedef struct B type_B; |
一定要记得初始化😭😭😭
「为什么我会输出乱码啊」「为什么会多输出几个字符啊」「为什么字符串长度和追加出错了啊」……
请再次检查,你是否对每一个变量、数组都初始化了。
我们讨论初始化,并不是说什么时候需要初始化、什么时候可以不初始化,而是说任何情况、不论全局还是局部,都必须初始化!
在任何地方都绝不允许写
int i;而必须写int i = 0;在任何地方都绝不允许写
char str[100];而必须写char str[100] = {0};设我们有结构体
1
2
3
4
5
6struct A {
int i;
double d;
char s[10];
int arr[10][20];
};在任何地方都绝不允许只写
struct A test[100];而必须写1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16struct A test[100];
/*****************************
以下初始化内容必须写!不许说麻烦。
*****************************/
for (int i = 0; i < 100; i++) { // 结构体数组必须初始化,且用循环初始化
test[i].i = 0;
test[i].d = 0.0;
for (int j = 0; j < 10; j++) { // 一维数组必须初始化,用循环初始化或用 memset
test[i].s[j] = '\0';
}
for (int j = 0; j < 10; j++) { // 二维数组必须初始化,且用循环初始化
for (int k = 0; k < 20; k++) {
test[i].arr[j][k] = 0;
}
}
}
另外关于memset的使用,我们只需要知道
仅能将所有元素初始化为 0
仅有如下的基本使用方法
1
2
3
4
5
6
7
8
9
10
11
12
13
char str[100];
memset(str, 0, sizeof(str));
int arr[100];
memset(arr, 0, sizeof(arr));
long long l_array[100];
memset(arr, 0, sizeof(l_array));
// memset 其他值是会出错的,可以试试如下代码
int a[10];
memset(a, 1, sizeof(a));
for (int i = 0; i < 10; i++) printf("%d ", a[i]);
补充
DevC++ 默认使用 C89 标准,此时局部变量仅能定义在函数开头。而我们很多时候见到的
for(int i = 0; ...)这种在后续代码中定义变量的形式,是从 C99 标准开始才支持的。解决方法如下
Step1:打开工具菜单
Step2:在下拉菜单中选择“编译选项”
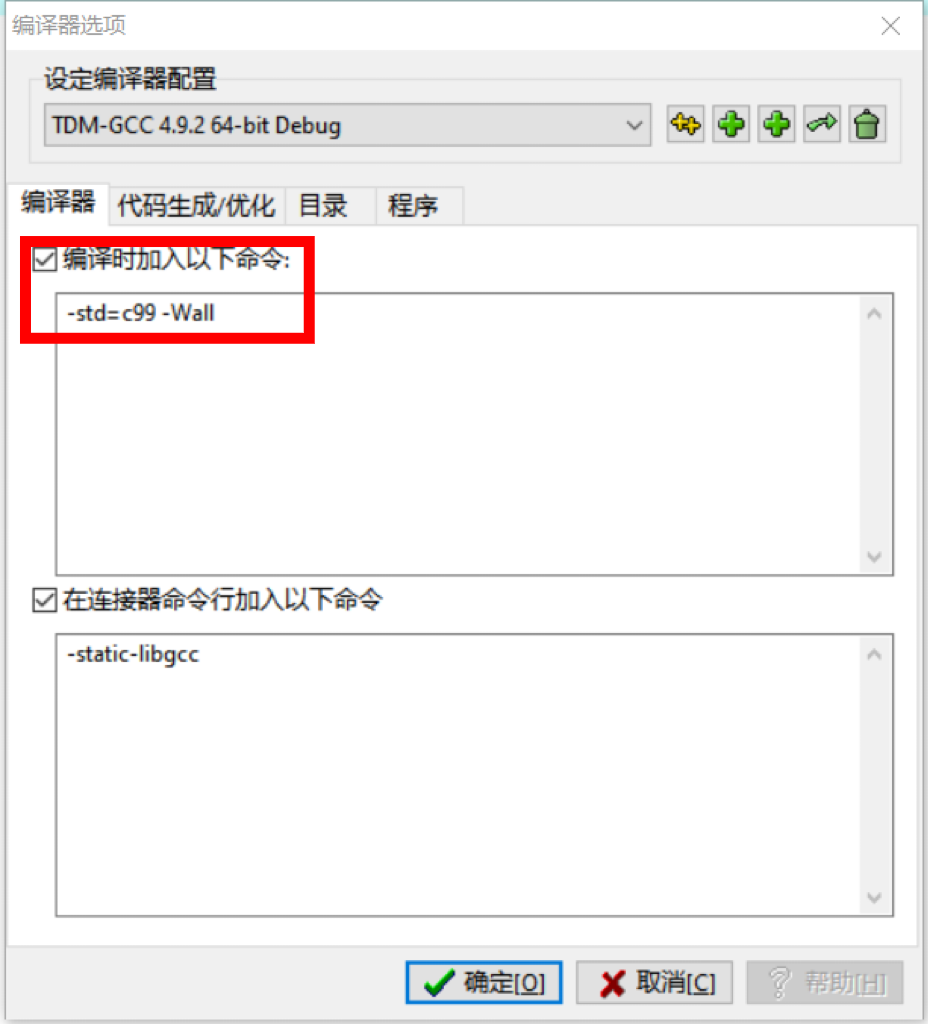
Step3:勾选“编译时加入以下命令”,加入
-std=c99 -Wall,点击“确定”。这两个选项,前者指定了使用 C99 标准,后者能帮我们输出更多警告信息。

sizeof
上文提到,sizeof返回对象的字节数大小,类型为size_t,可用%lu输出,用%d一般没有问题但是会给警告。
sizeof基本类型或其变量1
2
3
4
5
6
7sizeof(int); // int 的大小一般都是 4 个字节
int a = 10; // 如果想要使用与机器类型无关的整型变量,<stdint.h> 中有很多可供选择
sizeof(a);
sizeof(char*); // 32 位机器的指针大小为 4 字节,64 位机器则为 8 字节
double *p = NULL;
sizeof(p); // 指针大小固定,与所指的类型无关sizeof结构体类型或其变量1
2
3
4
5
6
7
8
9
10
11struct test {
int i;
char s[100];
};
sizeof(struct test);
struct test t1;
sizeof(t1);
// 注意,struct 的 size 并不一定等于其各个成员的 size 之和
// 具体原因可以自行百度 “结构体字节对齐”,此处不要求掌握sizeof数组名1
2
3
4
5
6
7
8
9
10
11
12
13int arr[100] = {0}; // 定义整型数组
int *p = arr; // 定义指针管理数组
sizeof(arr); // sizeof(数组名),返回数组总字节数,即 100 * sizeof(int)
sizeof(p); // sizeof(指向数组的指针),返回指针本身大小,与机器位数有关
sizeof(arr[0]); // sizeof(数组元素),返回单个元素的大小,即 sizeof(int)
char str[] = "Hello";
char *q = "World";
sizeof(str); // 返回 6
sizeof(q); // 返回 4(32位机器) 或 8(64位机器)
strlen(str); // 返回 5
strlen(q); // 返回 5
二维数组
在一些较复杂的项目中,除了声明必要的结构体之外,往往需要借助多维数组、并在函数原型中声明多维数组,特别是二维数组。使用二维数组时有很多易忽略的点,我们希望在接下来的内容中帮助大家更深地了解二维数组的本质,并尽量减少编程时 bug 的产生。
二维数组的存储
二维数组,也可以看成一个一维数组,这个一维数组中的每个元素都是一个一维数组。
因此,若将二维数组的每一行当做一个存储一维数组的元素,所有行汇集成一个一维数组,每个一维数组中各元素是连续存储的,那么就很容易理解:二维数组中的各元素在内存中是按照行优先的原则,进行连续存储。
例如,我们定义数组a[2][6],那么其在内存中从某一地址开始,存储情况如下图:

那么该数组中某个元素a[i][j]的地址&a[i][j]可以通过如下方式求得:首地址 + 单个元素长度 * (总列数 * i + j)。
由此可知,若想知道该二维数组中某一元素的地址,就必须知道该数组的数据类型和列数,这样才能实现对二维数组中某一个元素的精确访问,这也是为什么我们在声明二维数组以及把一个二维数组当作形参传递时,必须指定列数,否则就会报错。
我们来看如下几行代码:
1 | void print_two_dim(int a[][], int b); // error:没有指定列数 |
二维数组的指针访问
在此,我们推荐两种访问二维数组的方法,但不代表访问它的方法仅有如下两种。
指向元素的指针
这种方法最简单直接,现有如下代码:
1 | int a[2][6] = {{1, 2, 3, 4, 5, 6}, {7, 8, 9, 10, 11, 12}}; |
在此种定义下,访问数组a中的每一个元素只需要将p指针依次往后推,利用 4.1 中求某元素地址的方式即可实现精确访问。在该例子中,我们便知道了&a[i][j] == p + sizeof(int) * (6 * i + j)。
列指针
这种方式通过定义指针指向二维数组的某一行的第一列,再在此基础上访问该行的某个元素,现有如下代码:
1 | int a[2][6] = {{1, 2, 3, 4, 5, 6}, {7, 8, 9, 10, 11, 12}}; |
由此,指针数组p中第一个元素为二维数组a中第一行第一个元素的地址(意即第一行的首地址),第二个元素为二维数组a中第二行第一个元素的地址(意即第二行的首地址)。
在该例子中,我们便知道了&a[0][j] == p[0] + sizeof(int) * j 以及&a[1][j] == p[1] + sizeof(int) * j。
二维数组的形参传递
我们在 4.1 中已经提到,当我们把一个二维数组作为形参传递进入另一个函数里(例如有些同学做第二次作业的五子棋危险判断)时,一定要指定列数。在此我们也推荐两种写法。
数组法
1 |
|
请注意:以下传递方式无效,不能将二维数组的真实行数传入函数中:
1 | void print_two_dim(int a[2][6]); |
原因是:如同一维数组的形参传递一样,传入的数组被转化为指针,函数内部无法获取该数组大小。
1 | // 以下两种传递方式等效 |
数组指针法
数组指针指向二维数组,有些教材称这种指针为行指针,顾名思义就是操纵一行的指针。
1 |
|
在上述代码中,我们用数组指针来接收,也必须指定有 6 列,这是为了告诉内存,第二行从哪儿开始存放。
因此,形参中的(*a)[6]中,**a指向二维数组第一行的地址。***a就是二维数组第一个元素的地址,**a才能找到第一个元素的具体值,为 1。
char型二维数组
我们在 4.1 中提到,二维数组的存储方式为按行优先,连续存储。另一层意思就是说,二维数组里每一行所代表的一维数组是连续的,并非毫无关联。如果你并没有领略到这一层意思,那么请看如下代码:
1 |
|
代码的运行结果:
1 | abcdefghijklmnopqrstuvwxyzabcdefg |
诶!按照惯性思维,你会发现:我第一次打印时明明只想让他打印出二维数组第一行的值,为啥它把第二行的值一起打印出来了呢?
相信大家一定知道,printf("%s",a)这样一段代码,其本质上是从字符串数组a的首地址开始打印,知道遇到字符串终止字符(也就是'\0')停止。
那么再回到上述代码,由于二维数组的顺序存储特性,test[1][0]元素是紧跟在test[0][25]元素之后的,也就是说当输出test[0][25]元素时,系统发现该元素之后并不是'\0',而是一个有着具体值的字符,于是就会接着输出,直到遇到'\0'为止。于是,我们通过让test[1][0]='\0',成功地让输出停留在test[0][25]的位置上,实现了只输出第一行的目的。
这也告诉我们,当我们使用char类型二维数组时,首先需要初始化,且尽量不要让该数组的列数小到恰好等于我们想让它存储的数据个数,否则就会像上述例子一样,每一行末尾没有'\0',在进行后续的按行操作时出现 bug。
Author: diandian, Riccardo(Version Grey)
- Title: 猪脚说第三期
- Author: Diandian
- Created at : 2023-07-14 17:46:08
- Updated at : 2023-07-14 17:54:22
- Link: https://cutedian.github.io/2023/07/14/猪脚说第三期/
- License: This work is licensed under CC BY-NC-SA 4.0.